The last few months and years have seen a wave of AI integration across multiple sectors, driven by new technology and global enthusiasm. There are copilots, summarization models, code assistants, and chatbots at every level of an organization, from engineering to HR. The impact of these models is not only professional, but personal: enhancing our ability to write code, locate information, summarize dense text, and brainstorm new ideas.
This may all seem very recent, but AI has been woven into the fabric of cybersecurity for many years. However, there are still improvements to be made. In our industry, for example, models are often deployed on a massive scale, processing billions of events a day. Large language models (LLMs) – the models that usually grab the headlines – perform well, and are popular, but are ill-suited for this kind of application.
Hosting an LLM to process billions of events requires extensive GPU infrastructure and significant amounts of memory – even after optimization techniques such as specialized kernels or partitioning the key value cache with lookup tables. The associated cost and maintenance are infeasible for many companies, particularly in deployment scenarios, such as firewalls or document classification, where a model has to run on a customer endpoint.
Since the computational demands of maintaining LLMs make them impractical for many cybersecurity applications – especially those requiring real-time or large-scale processing – small, efficient models can play a critical role.
Many tasks in cybersecurity do not require generative solutions and can instead be solved through classification with small models – which are cost-effective and capable of running on endpoint devices or within a cloud infrastructure. Even aspects of security copilots, often seen as the prototypical generative AI use case in cybersecurity, can be broken down into tasks solved through classification, such as alert triage and prioritization. Small models can also address many other cybersecurity challenges, including malicious binary detection, command-line classification, URL classification, malicious HTML detection, email classification, document classification, and others.
A key question when it comes to small models is their performance, which is bounded by the quality and scale of the training data. As a cybersecurity vendor, we have a surfeit of data, but there is always the question of how to best use that data. Traditionally, one approach to extracting valuable signals from the data has been the ‘AI-analyst feedback loop.’ In an AI-assisted SOC, models are improved by integrating rankings and recommendations from the analysts on model predictions. This approach, however, is limited in scale by manual effort.
This is where LLMs do have a part to play. The idea is simple yet transformative: use big models intermittently and strategically to train small models more effectively. LLMs are the most effective tool for extracting useful signals from data at scale, modifying existing labels, providing new labels, and creating data that supplements the current distribution.
By leveraging the capabilities of LLMs during the training process of smaller models, we can significantly enhance their performance. Merging the advanced learning capabilities of large, expensive models with the high efficiency of small models can create fast, commercially viable, and effective solutions.
Three methods, which we’ll explore in-depth in this article, are key to this approach: knowledge distillation, semi-supervised learning, and synthetic data generation.
- In knowledge distillation, the large model teaches the small model by transferring learned knowledge, enhancing the small model’s performance without the overhead of large-scale deployment. This approach is also useful in domains with non-negligible label noise that cannot be manually relabeled
- Semi-supervised learning allows large models to label previously unlabeled data, creating richer datasets for training small models
- Synthetic data generation involves large models producing new synthetic examples that can then be used to train small models more robustly.
Knowledge distillation
The famous ‘Bitter Lesson’ of machine learning, as per Richard Sutton, states that “methods that leverage computation are ultimately the most effective.” Models get better with more computational resources and more data. Scaling up a high-quality dataset is no easy task, as expert analysts only have so much time to manually label events. Consequently, datasets are often labeled using a variety of signals, some of which may be noisy.
When training a model to classify an artifact, labels provided during training are usually categorical: 0 or 1, benign or malicious. In knowledge distillation, a student model is trained on a combination of categorical labels and the output distribution of a teacher model. This approach allows a smaller, cheaper model to learn and copy the behavior of a larger and more well-learned teacher model, even in the presence of noisy labels.
A large model is often pre-trained in a label-agnostic manner and asked to predict the next part of a sequence or masked parts of a sequence using the available context. This instills a general knowledge of language or syntax, after which only a small amount of high-quality data is needed to align the pre-trained model to a given task. A large model trained on data labeled by expert analysts can teach a small student model using vast amounts of possibly noisy data.
Our research into command-line classification models (which we presented at the Conference on Applied Machine Learning in Information Security (CAMLIS) in October 2024), substantiates this approach. Living-off-the-land binaries, or LOLBins, use generally benign binaries on the victim’s operating system to mask malicious behavior. Using the output distribution of a large teacher model, we trained a small student model on a large dataset, originally labeled with noisy signals, to classify commands as either a benign event or a LOLBins attack. We compared the student model to the current production model, shown in Figure 1. The results were unequivocal. The new model outperformed the production model by a significant margin, as evidenced by the reduction in false positives and increase in true positives over a monitored period. This approach not only fortified our existing models, but did so cost-effectively, demonstrating the use of large models during training to scale the labeling of a large dataset.
Figure 1: Performance difference between old production model and new, distilled model
Semi-supervised learning
In the security industry, large amounts of data are generated from customer telemetry that cannot be effectively labeled by signatures, clustering, manual review, or other labeling methods. As was the case in the previous section with noisily labeled data, it is also not feasible to manually annotate unlabeled data at the scale required for model improvement. However, data from telemetry contains useful information reflective of the distribution the model will experience once deployed, and should not be discarded.
Semi-supervised learning leverages both unlabeled and labeled data to enhance model performance. In our large/small model paradigm, we implement this by initially training or fine-tuning a large model on the original labeled dataset. This large model is then used to generate labels for unlabeled data. If resources and time permit, this process can be iteratively repeated by retraining the large model on the newly labeled data and updating the labels with the improved model’s predictions. Once the iterative process is terminated, either due to budget constraints or the plateauing of the large model’s performance, the final dataset – now supplemented with labels from the large model – is utilized to train a small, efficient model.
We achieved near-LLM performance with our small website productivity classification model by employing this semi-supervised learning technique. We fine-tuned an LLM (T5 Large) on URLs labeled by signatures and used it to predict the productivity category of unlabeled websites. Given a fixed number of training samples, we tested the performance of small models trained with different data compositions, initially on signature-labeled data only and then increasing the ratio of originally unlabeled data that was later labeled by the trained LLM. We tested the models on websites whose domains were absent from the training set. In Figure 2, we can see that as we utilized more of the unlabeled samples, the performance of the small networks (the smallest of which, eXpose, has just over 3,000,000 parameters – approximately 238x less than the LLM) approached the performance of the best-performing LLM configuration. This demonstrates that the small model received useful signals from unlabeled data during training, which resemble the longtail of the internet seen during deployment. This form of semi-supervised learning is a particularly powerful technique in cybersecurity because of the vast amount of unlabeled data from telemetry. Large models allow us to unlock previously unusable data and reach new heights with cost-effective models.
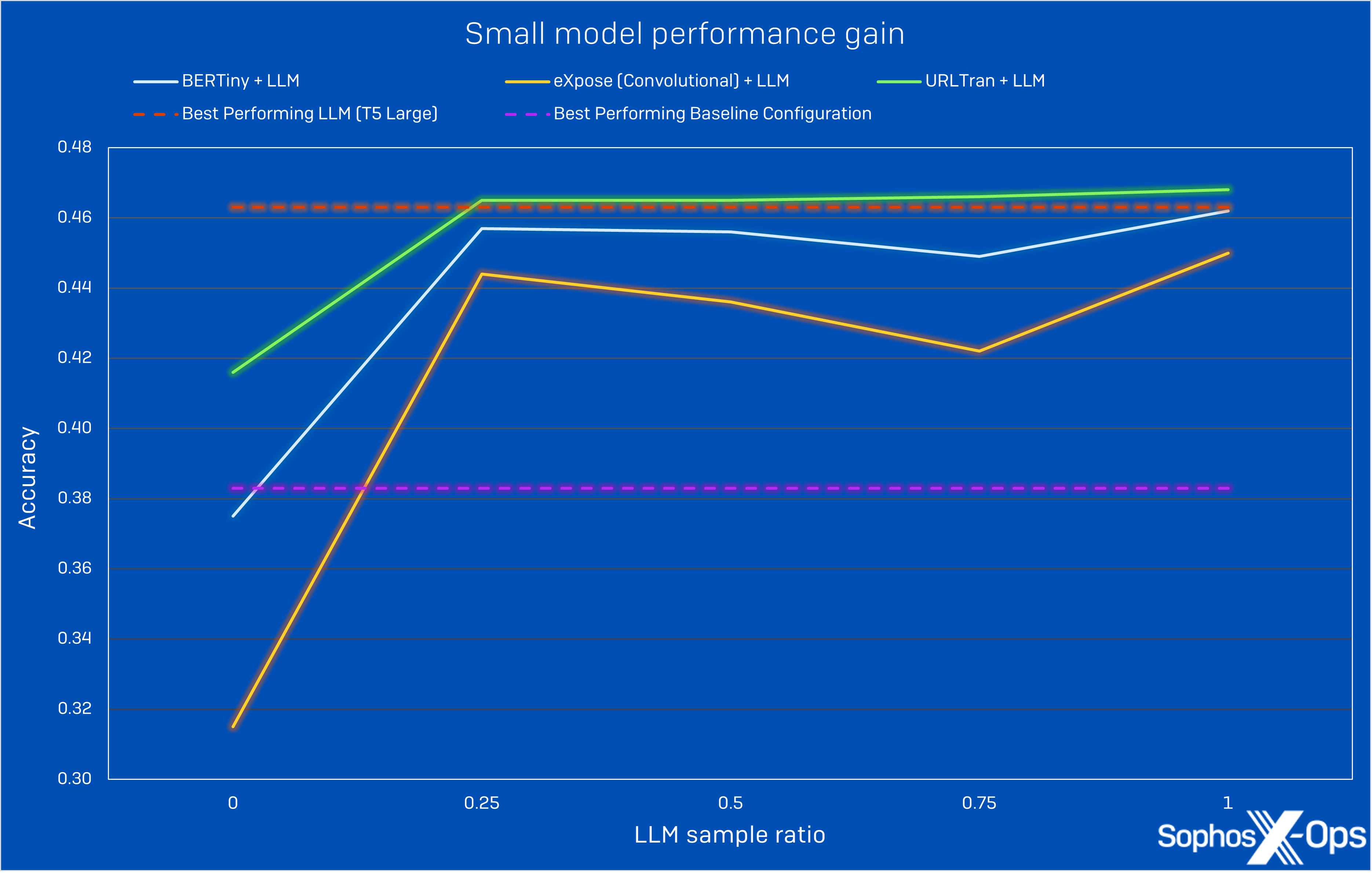
Figure 2: Enhanced small model performance gain as quantity of LLM-labeled data increases
Synthetic data generation
So far, we have considered cases where we use existing data sources, either labeled or unlabeled, to scale up the training data and therefore the performance of our models. Customer telemetry is not exhaustive and does not reflect all possible distributions that may exist. Collecting out-of-distribution data is infeasible when performed manually. During their pre-training, LLMs are exposed to vast amounts – on the magnitude of trillions of tokens – of recorded, publicly available knowledge. According to the literature, this pre-training is highly impactful on the knowledge that an LLM retains. The LLM can generate data similar to that it was exposed to during its pre-training. By providing a seed or example artifact from our current data sources to the LLM, we can generate new synthetic data.
In previous work, we’ve demonstrated that starting with a simple e-commerce template, agents orchestrated by GPT-4 can generate all aspects of a scam campaign, from HTML to advertising, and that campaign can be scaled to an arbitrary number of phishing e-commerce storefronts. Each storefront includes a landing page displaying a unique product catalog, a fake Facebook login page to steal users’ login credentials, and a fake checkout page to steal credit card details. An example of the fake Facebook login page is displayed in Figure 3. Storefronts were generated for the following products: jewels, tea, curtains, perfumes, sunglasses, cushions, and bags.
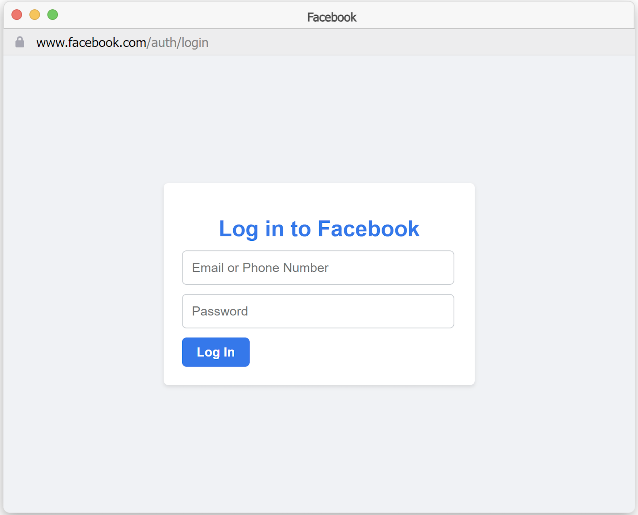
Figure 3: AI-generated Facebook login page from a scam campaign. Although the URL seems real, it is a fake frame designed by the AI to appear real
We evaluated the HTML of the fake Facebook login page for each storefront using a production, binary classification model. Given input tokens extracted from HTML with a regular expression, the neural network consists of master and inspector components that allow the content to be examined at hierarchical spatial scales. The production model confidently scored each fake Facebook login page as benign. The model outputs are displayed in Table 1. The low scores indicate that the GPT-4 generated HTML is outside of the production model’s training distribution.
We created two new training sets with synthetic HTML from the storefronts. Set V1 reserves the “cushions” and “bags” storefronts for the holdout set, and all other storefronts are used in the training set. Set V2 uses the “jewel” storefront for the training set, and all other storefronts are used in the holdout set. For each new training set, we trained the production model until all samples in the training set were classified as malicious. Table 1 shows the model scores on the hold out data after training on the V1 and V2 sets.
| Models | |||
| Phishing Storefront | Production | V1 | V2 |
| Jewels | 0.0003 | – | – |
| Tea | 0.0003 | – | 0.8164 |
| Curtains | 0.0003 | – | 0.8164 |
| Perfumes | 0.0003 | – | 0.8164 |
| Sunglasses | 0.0003 | – | 0.8164 |
| Cushion | 0.0003 | 0.8244 | 0.8164 |
| Bag | 0.0003 | 0.5100 | 0.5001 |
Table 1: HTML binary classification model scores on fake Facebook login pages with HTML generated by GPT-4. Websites used in the training sets are not scored for V1/V2 data
To ensure that continued training does not otherwise compromise the behavior of the production model, we evaluated performance on an additional test set. Using our telemetry, we collected all HTML samples with a label from the month of June 2024. The June test set includes 2,927,719 samples with 1,179,562 malicious and 1,748,157 benign samples. Table 2 displays the performance of the production model and both training set experiments. Continued training improves the model’s general performance on real-life telemetry.
| Models | |||
| Metric | Production | V1 | V2 |
| Accuracy | 0.9770 | 0.9787 | 0.9787 |
| AUC | 0.9947 | 0.9949 | 0.9949 |
| Macro Avg F1 Score | 0.9759 | 0.9777 | 0.9776 |
Table 2: Performance of the synthetic-trained models compared to the production model on real-world hold out HTML data
Final thoughts
The convergence of large and small models opens new research avenues, allowing us to revise outdated models, utilize previously inaccessible unlabeled data sources, and innovate in the domain of small, cost-effective cybersecurity models. The integration of LLMs into the training processes of smaller models presents a commercially viable and strategically sound approach, augmenting the capabilities of small models without necessitating large-scale deployment of computationally expensive LLMs.
While LLMs have dominated recent discourse in AI and cybersecurity, more promising potential lies in harnessing their capabilities to bolster the performance of small, efficient models that form the backbone of cybersecurity operations. By adopting techniques such as knowledge distillation, semi-supervised learning, and synthetic data generation, we can continue to innovate and improve the foundational uses of AI in cybersecurity, ensuring that systems remain resilient, robust, and ahead of the curve in an ever-evolving threat landscape. This paradigm shift not only maximizes the utility of existing AI infrastructure but also democratizes advanced cybersecurity capabilities, rendering them accessible to businesses of all sizes.

{kind=link}